
 290,409
290,409文|超聚焦
大模型集体跳水,还得怪DeepSeek?
4月24日,Minimax早盘大跌,一度下跌-12.64%,最低录得750港元;而智谱也同样在午盘后最多跌-12.85%,最低录得896港元。
而股价下跌的原因很简单,他们最大的潜在竞争对手DeepSeek回来了。
4月24日,中国深度求索公司正式上线全新系列模型DeepSeek-V4预览版,并同步开源。
据悉,DeepSeek-V4系列包含两个MoE模型版本,分别是满足高性能研发的DeepSeek-V4-Pro(下称DS-V4-Pro),以及满足经济高效部署需求的DeepSeek-V4-Flash(下称DS-V4-Flash)。

为啥DeepSeek每次一发模型就有AI产业链上的公司股价大跌?这次发布又利好了谁?
01 DeepSeek打破“小院高墙”
DeepSeek这次打破的,是想要靠闭源模型API调用赚钱的商业闭环。
过去两个月里,国内大模型赛道完成了一次静默转向,不少头部公司不约而同地走上同一条模型闭源,能力API化,价值按Token计费的路。
3月16日,智谱AI发布GLM-5-Turbo,为自2025年以来的智谱首个闭源模型,定位为针对其OpenClaw Agent框架深度优化的基座模型。
搞个Turbo做闭源,是因为GLM-5-Turbo是为智谱自家的OpenClaw Agent框架深度优化的。如果想用这个模型最好的Agent能力,就得用OpenClaw,用OpenClaw,就得调智谱的API,调API,也得按Token付费。
3月底,阿里也快速上线了三款新发的Qwen模型,这三款Qwen模型全部闭源。不开放权重下载,只能通过阿里云平台调用。
阿里的逻辑也很清晰,云厂商的算力基础设施已经铺好了,模型就是往上卖的增值服务。你租我的GPU是花钱,调我的模型也是花钱,最好是两边都花。
而打着开源模型旗号的Minimax 2.7,也被海外社区用户叫做“假开源”。原因是MiniMax悄悄更换了MiniMax2.7模型的开源协议,将标准MIT协议变为Modified-MIT协议,原本允许无限制商用、仅需保留版权声明的核心条款被推翻,所有商业用途必须获得MiniMax授权,且未设置营收豁免门槛。
换句话说,就是“我开源了,但你用Minimax 2.7几乎什么都做不了”。
你想拿MiniMax 2.7做个商业产品,要先给去打个报告。你想把它集成到公司的服务里,要先拿到授权。你是年收入100万的小团队?不好意思,没有豁免。
几家大模型企业下来,一套组合拳给用户们安排的可是明明白白,但开发者、调用者们又很难跳起来骂“不讲武德”。
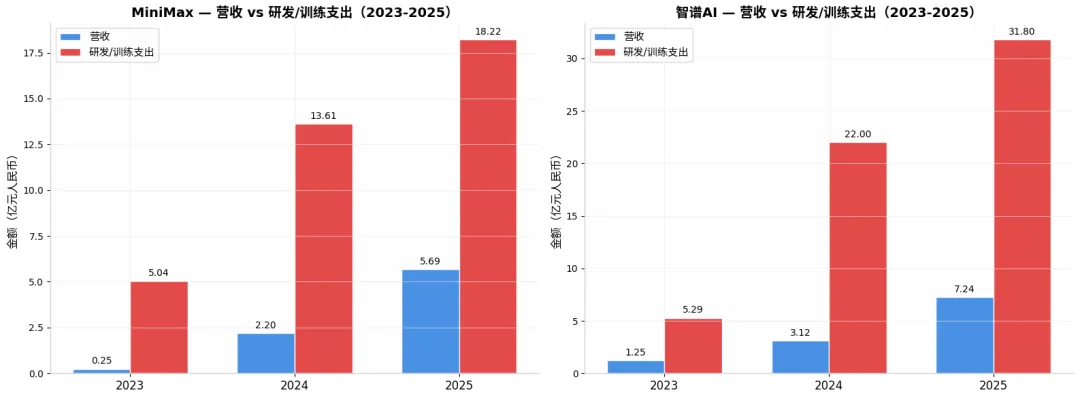
智谱2025年全年收入7.24亿元人民币,同比增长131.9%,增速确实亮眼。但翻到支出栏:研发开支31.80亿元,是收入的4.4倍。净亏损47.18亿元,较上年扩大59.5%。换句话说,智谱每赚1块钱,就要在研发上烧掉4块4毛钱。
隔壁MiniMax,也没好到哪去,2025年总收入7903.8万美元(约合5.6亿元人民币),同比增长158.9%。研发开支2.53亿美元,是收入的3.2倍。年内亏损18.72亿美元,当然这里面大部分是上市相关的金融负债公允价值变动,即便如此,每赚1美元研发上也要花掉3.2美元。
不过,这口“闭源”API调用的饭还没吃几口,就来了个掀锅的。
DeepSeek-V4预览版的两个模型权重全丢到Hugging Face和ModelScope上,想下就下,想改就改。
说实话,DS-V4-Pro在硬指标上能不能锤爆GPT-5.1或者Gemini Ultra 3.0?目前看还差点意思。DeepSeek自己的技术报告里的数据很清楚:世界知识方面稍逊于Gemini-Pro-3.1,Agent能力离Opus 4.6的思考模式也还有一段距离。
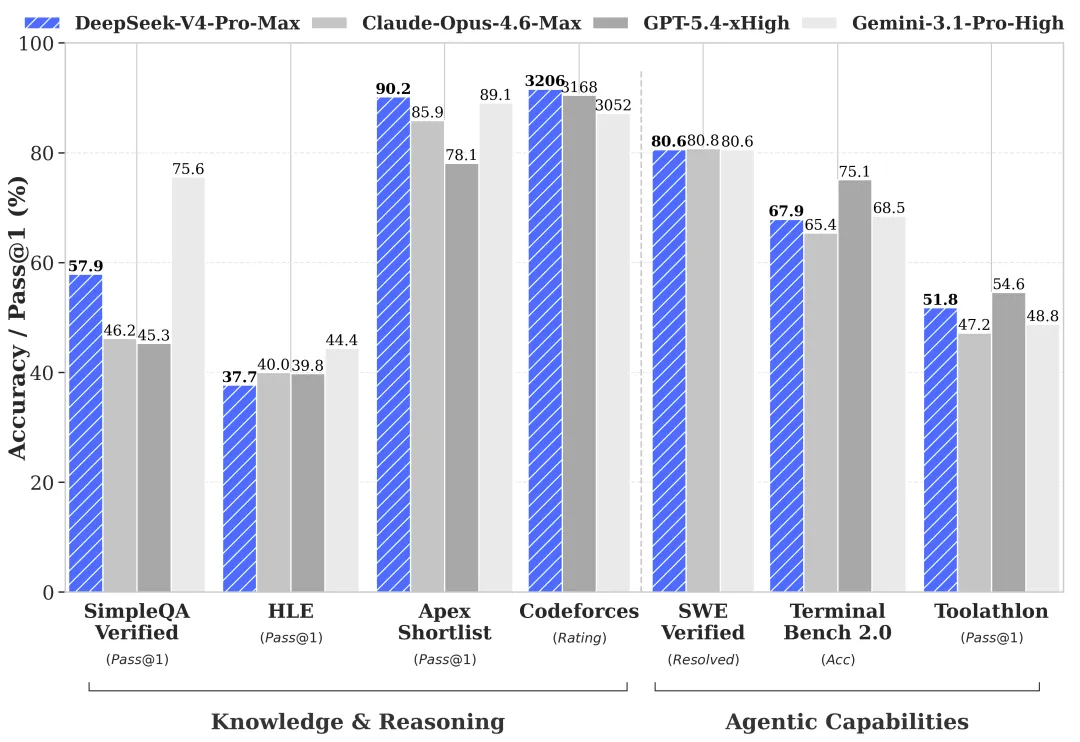
但问题是,国内友商们走的也不是在性能上对标OpenAI、Google和Anthropic的道路。
以Openrouter为例,虽然Minimax、Kimi、智谱的性能比起Claude稍逊,但价格大多都在1/5到1/10的区间,主打的是性价比。毕竟,GPT-5的API调用价格摆在那里,Gemini的算力账单也不是谁都扛得住。而国内企业的需求其实没那么极致,80分的效果,配上20分的价格,性价比就够了。
于是,一条默契的商业路径形成了,大家心照不宣地做闭源,定价卡在“比海外便宜一个数量级、比开源部署省事儿”的黄金区间。
企业客户一算账,发现租卡部署开源模型运维成本不低,效果还不一定稳;调用国产闭源API,反而便宜、省心、效果够用。
直到DeepSeek来之前,这笔账,一直都算得过来。
DeepSeek用的方式,其实就是这几家大模型的“回头路”:效果不差,成本更低,而且还开源。你API收多少钱,我自己部署或者去第三方平台上购买成本都打个对折甚至更多,效果还能持平。你绑框架、改协议、设门槛,我MIT协议一键下载,连商用授权都懒得卡。
历史总是相似的。上一轮,DeepSeek-V2把国产大模型的价格打下来一大截。这一轮,V4带着百万上下文和开源协议,怕是要把“闭源收费”这条路彻底堵死。
接下来会有多少家友商,默默把自己的模型权重又传回Hugging Face?
02 这次DeepSeek救了恒科一命
不过,DeepSeek也不是只会“搞破坏”,另一半的故事,藏在恒生科技指数的K线图里。
今日随着DeepSeek-V4预览版正式官宣,港股应声大涨。
最先受益的是芯片制造环节,华虹半导体盘中涨超17%,中芯国际涨超10%,整个芯片板块集体反攻。紧随其后的是互联网AI相关公司,联想、阿里巴巴、百度等纷纷领涨,恒生科技指数从-1.8%的深坑里硬生生爬了出来。
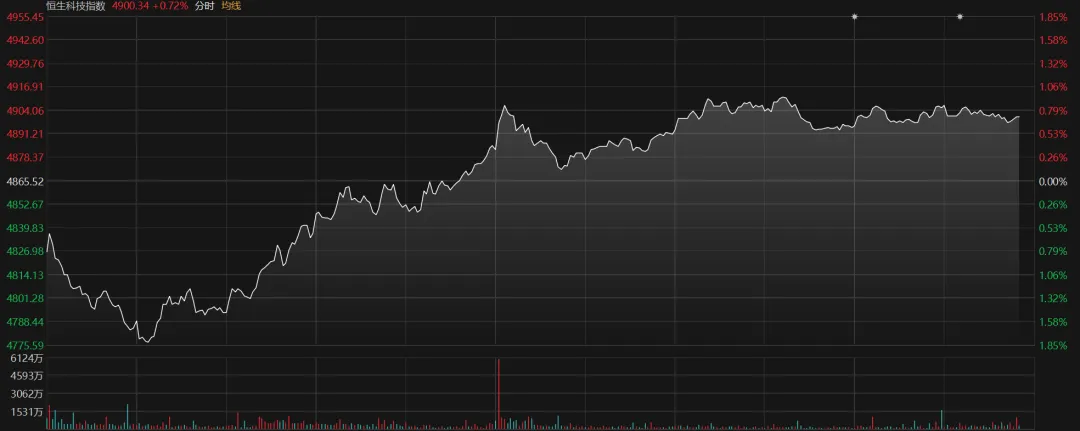
这场景,似曾相识。
2025年初,DeepSeek第一次亮相,给当时处于估值洼地的港股互联网板块注入了一剂强心针。那次是“救了一命”。这次,DeepSeek又捞了恒科一把。
但两次上涨的逻辑,本质不同。
上一次,市场炒的是“AI概念”,国内终于有公司能追上了,情绪驱动。这一次,资本的兴奋点从概念下沉到了技术底层,芯片制造板块涨幅最大,其次是具备真实AI落地场景的应用公司。
因为DeepSeek-V4做了一件比“开源”更狠的事,它主动拥抱了国产算力。
在DeepSeek-V4的技术文档里,有一行不起眼的小字,却可能是整份文档里最重要的一句话:“受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。”
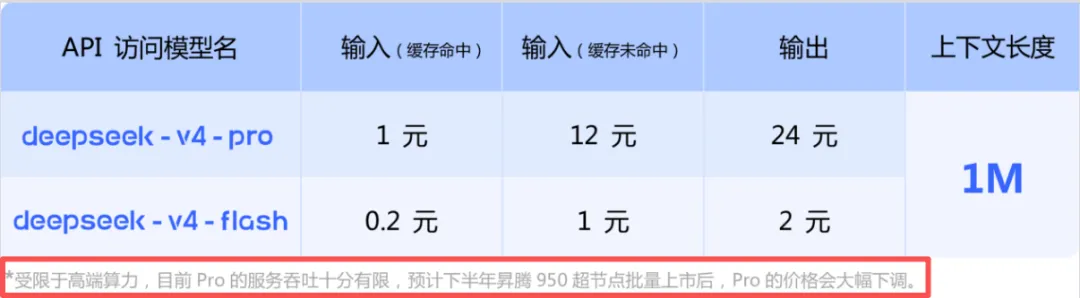
言下之意是现在没放开跑,不是因为技术不行,是因为能用的国产算力还不够多,等华为的昇腾950超节点大批量上线,我还能更便宜。
这句话对于国产算力产业链来说,不亚于一针强心剂。因为再次验证了一件事:国产芯片,真的能跑国产的旗舰大模型了。
而华为也第一时间表示,昇腾超节点系列产品全面支持DeepSeek V4。
按照华为官方说法,昇腾一直同步支持DeepSeek系列模型,本次通过双方芯模技术紧密协同,实现昇腾超节点全系列产品支持DeepSeek V4系列模型。
所以你看,DeepSeek做多的,从来不只是某一只股票。
它做多的是国产算力产业链,让资本市场相信,国产芯片不仅能造出来,还能跑得动大模型。
它做多的是AI应用的商业化前景,当推理成本降到原来的数十分之一,那些原本“算不过来账”的场景,开始有了商业可行性。
它做多的是开发者选择权的自由。而这,才是开源最性感的注脚。
有人说,DeepSeek每次发模型都是在“献祭式”定价。但换个角度看,这也许不是献祭,而是加速。
加速算力国产化的进程,加速AI普惠的到来,加速那些躺在闭源温床上数钱的商业模式,被时代抛进垃圾桶。
至于那些着急发模型、但能力又不足的大厂——DeepSeek已经在官网用一句话定了调:
“不诱于誉,不恐于诽,率道而行,端然正己。”
大家自己对号入座吧。

