中文通用大模型基准测试 SuperCLUE 发布,ChatGPT居首、讯飞星火国内第一
蓝鲸财经2023-05-10 10:45
 94,108
94,108结果显示,国产大模型中,科大讯飞研发的星火认知大模型总排名第三,国内排名第一。

蓝鲸教育5月10日讯,日前,中文通用大模型综合性评测基准 SuperCLUE 正式发布。该基准测试可通过多个维度,考验目前市面上主流的中文 GPT 大模型的能力。
利用 SuperCLUE 测试基准,该机构对市面上主流的支持中文的通用大模型进行了评测与排名。结果显示,GPT-4 排名第一,已经非常接近人类的能力。
国产大模型中,科大讯飞研发的星火认知大模型总排名第三,国内排名第一。由于大模型不断迭代,该排行榜会定期更新,并于CLUEbenchmarks官方网站公示。
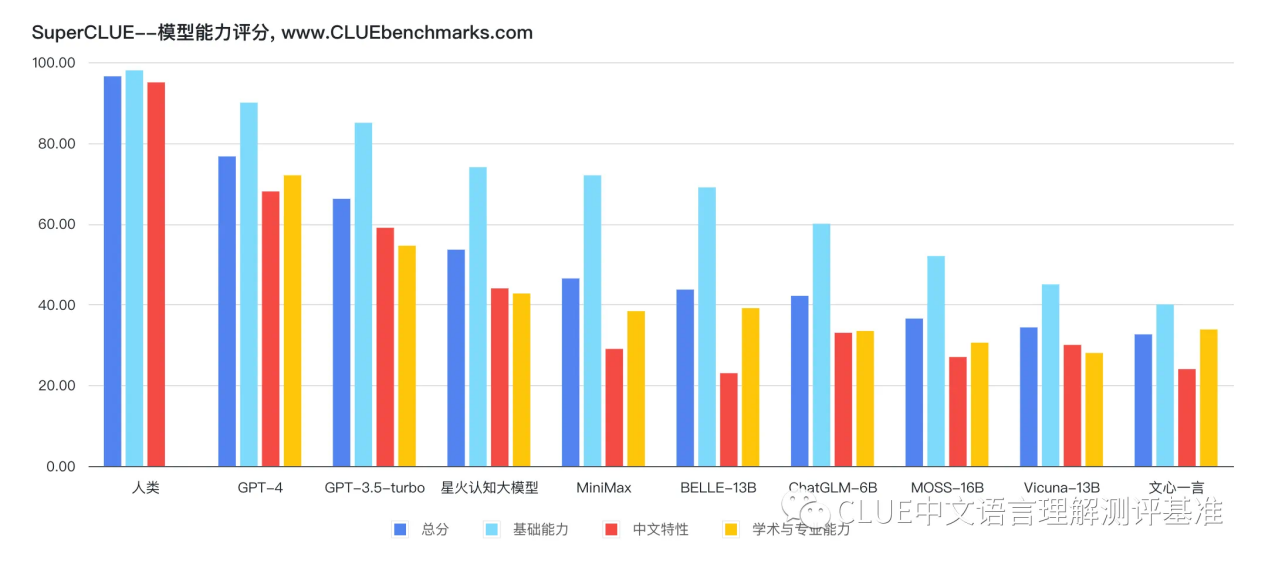
据介绍,该基准测试关注的问题包括:中文大模型在不同任务上的表现如何?与国际代表性模型相比,中文大模型的表现达到了何种程度?中文大模型与人类表现相比如何?SuperCLUE 测试基准可以考验目前市面上主流的中文 GPT 大模型的能力,评测维度涵盖基础能力、专业能力、中文特性。
*特别声明:文章内容仅供参考,不构成投资建议。投资者据此操作风险自担。

