
 137,751
137,751文|光子星球 郝鑫
编辑|吴先之
6.18卷价格的风吹到了大模型圈。
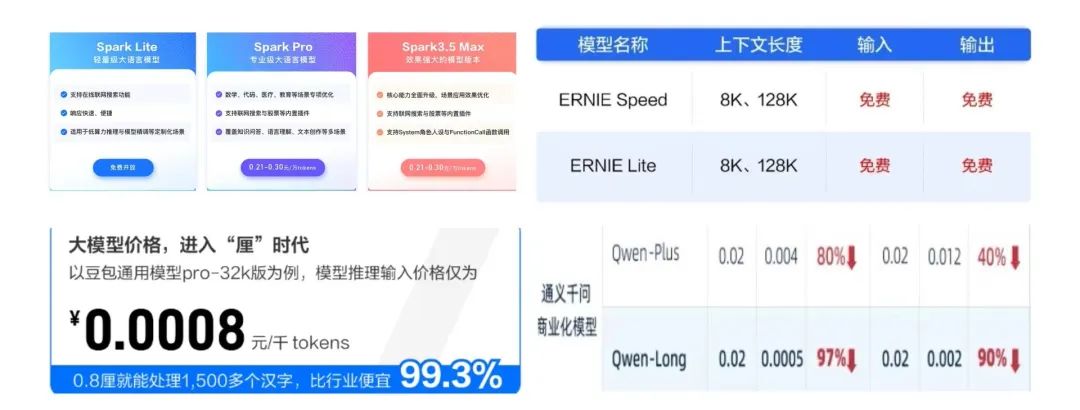
5月15日,火山引擎率先亮剑,宣布豆包主力模型在企业市场定价为0.0008元/千 tokens,较行业便宜99.3%。其精准狙击同行的做法,直接掀起了一场大模型厂商低价肉搏战。
阿里、百度、科大讯飞、腾讯纷纷站出来应战。
5月21日,阿里云官宣通义千问主力模型Qwen-Long输入价格降至0.0005元/千 tokens,直降97%;仅隔了几个小时,百度智能云祭出必杀技,宣布文心大模型两大主力模型ERNIE Speed、ERNIE Lite全面免费。
自百度之后,大模型彻底与免费挂上了钩。
5月22日,科大讯飞宣布讯飞星火Lite API永久免费开放。下午,腾讯云公布全新大模型升级方案,主力模型之一的混元-lite模型调整为全面免费。
仅仅一周,大模型从“厘”时代跨入了“免费”时代。
表面是降价,背后的根本驱动力来自于技术。在经历过一年多的技术追赶后,国内大模型厂商在算力、推理、算法等多个层面都实现了突破,从而实现了技术方面的降本。再加之大厂云计算所带来的规模化优势,才共同引发了降价潮。
从另一方面也侧面印证了,大模型从发布会demo进入了可用的新阶段。火山引擎总裁谭待谈到豆包大模型发布和降价时间点时提到了一个标准:“模型能力准备好了”。当下,各大模型厂商能够大范围开放使用的前提就是,模型能力通过测试,并且能够稳定供给。
细究之下,大模型厂商的低价、免费,更像是引诱老鼠出洞的奶酪。
这种免费带有诸多限制,阿里、百度降价幅度最高的产品都是其偏轻量化的模型版本,仅适用于使用频次不高、推理量不太大、任务处理量不太复杂的中小企业、开发者短期使用。
在这种情况下,低价、免费这些“互联网”手段沦为了大模型厂商的获客策略,一边获得更多的数据来优化模型效果,一边试图通过尝鲜来向更高阶的付费版本转化。
买得精不如卖得精,大模型厂商集体降价的背后仍有一系列问题值得探讨。
用互联网免费大法卖AI大模型
从使用者的角度考虑,大模型降价潜在的受益对象可能有两类:开发者和企业。
虽然行业内大规模降价是第一次,但早在去年,各大厂就通过赢黑客松比赛送token的方式,来吸引AI创业者和团队的参与。
当时,就有黑客松常客告诉光子星球,“参加比赛就是薅羊毛,token不拿白不拿”。
薅羊毛确实可以降低创业成本。把价格打下来,对开发者特别是独立开发者而言是友好的。这可能意味着开发者可以多跑几圈测试,多获得几轮反馈数据,从而缩短产品上线的周期,进一步提升创业成功的可能性。
但前提是得满足开发者和企业的需求。光子星球了解到,降价的消息传出后,在开发者和企业当中呈现出了两极化的声音。
一方对国内大模型降价比较赞同,认为开发者和企业可以继续薅羊毛,毕竟现在市场上套壳应用产品的案例不在少数;另一方则觉得,大模型厂商的降价缺乏诚意,大幅降价的都是小规模模型,虽然对外声称水平可以对标GPT-4,但实际上连GPT-3.5都不如,模型水平不达标,根本无法在实际的生产环境中运行。
大模型厂商表面上的降价,实则背后暗藏玄机。这好比给了你一个云盘限时体验卡,刚看了三秒的高清视频就弹出来升级VIP的提醒,也是恰巧刚体验了5秒极速下载,就提醒你升级会员权限。
大模型的尝鲜也是大差不差,打着降价、免费的噱头,把开发者和企业吸引过来使用,才刚上手,就被开始卡调用速度、推理速度、任务处理量等关键指标。
而且,光子星球进一步发现,大模型厂商的降价策略并未对商业化造成实质性影响。呈现的结果就是,大模型厂商价格降了,钱也没少赚。
某大厂内部人士告诉光子星球,大模型目前主要的商业化方式是拿to B订单。类似于SaaS和云的合作模式,存在case by case和合作提成两种方式。
其中,case by case是更为主流的合作方式,即大模型厂商的现有客户会因为本来就在使用某一厂商的云和SaaS产品,顺带着开始尝试该厂商的大模型。相应地,大模型厂商为了留住客户,也会在自家SaaS和云产品上增加AI的功能。
这样一来可能造成如下情况:大模型变成了SaaS产品或者项目合作的增值要素。大模型本身不付费,但为了对冲成本,大模型厂商得反过来提高SaaS和项目合作的价格。羊毛最终出在羊身上,价格的一升一降,大厂非但没亏反而照赚不误。
大模型降价了,然后呢?
或许国内大模型价格战的影响在于,从现在起,大模型正式与“免费”划上了等号。
这将成为一次分水岭,过去两年,一众创业者和团队试图建立的“上线即收费”的AI原生产品逻辑再次受到挑战。兜兜转转,互联网的商业逻辑再次主导了大模型的发展。
无论国内外,行业中一直都存在着模型混用的状态。本质上在于各家大模型各有所长,比如ChatGPT擅理,Claude擅文,正是基于不同模型的特性,用户在不同的使用场景就会调取相应地模型。
类似的情况也发生在中国,我们了解到,金山办公在研发WPS AI功能的过程中,就轮流尝试了MiniMax、智谱AI、文心一言、商汤日日新、通义千问等大模型能力,通过了解各家大模型的优势来搭建自己的平台。
去年,国内一家做数据治理的公司曾告诉光子星球,他们也会在前期大量地跑模型,测试不同模型的能力,在不同任务中择优调取大模型的能力。这样既进行了成本测试,也能避免对单一产品过度依赖。
到现在为止,大模型产品时常被人诟病用户黏性不高。相比于订阅收费,按API调取收费的方式本就难以留客。
企业侧的case by case收费模式亦是如此,企业使用某一家厂商的大模型周期,取决于订单周期。客户跟着订单走,今天用字节,明天也可以用阿里。
降价的本质是要加速大模型落地。大模型不能只停留在写诗作画,还得“下基层”。降价的背后是通过触达千行百业和获取更大样本容量的合作案例,从中提取共性特征,形成合理、高效的大模型行业标准。
当大模型厂商再次拉回到了同一起跑线上,在各家模型能力水平相近,价格不相上下的情况下,他们所要面临的共同课题变成了如何留住客户。
而站在大模型客户的角度,他们更希望通过对冲,减少对单一模型的依赖。在这样的心理驱动之下,未来的大模型模式可以参考SaaS和云产品的采购方式,一家公司内部可以购买多家大模型公司产品,不同的产品线和业务部门也可能使用不同家的大模型。
赢了价格,就赢了一切吗?
回顾历史,大模型一路从百模、参数、长文本打到了现在的价格。过去的经验告诉我们,价格不可能是唯一的决定因素。
即使不谈企业和开发者拿到手的东西对不对版,大模型厂商给出的价格在市场上也不是很有竞争力。
比国内大模型更具性价比的是开源大模型。一位国内负责电商代运营业务的工作人员告诉光子星球,截至目前为止,自己业务部门购买过ChatGPT、Midjourney等AI相关的付费产品,现在底层使用的是开源且可商用的Llama 3。
一些公司和开发者更倾向部署开源模型的原因在于,一方面国外Llama等开源模型的能力一直在追赶最强版本ChatGPT的水平,一些通用场景能力在业务中足够用。另一方面,从头部署和精调模型,对后期业务调整也更灵活。
此外,光子星球发现,在闭源的大模型原厂和开源社区中间,还衍生出了中间商角色。一个令人费解的现象正在大模型行业蔓延:大模型分销商卖的API价格比原厂价格还便宜。
以国外Deepbricks平台为例,最新上架的GPT-4o模型,OpenAI官方输入价格为5美元/1M tokens,而Deepbricks自身的售价只要2美元/1M tokens。如果这些中间商真的能做到实时更新模型能力,还能做到低价,以后可能会吸引一批开发者和企业使用。
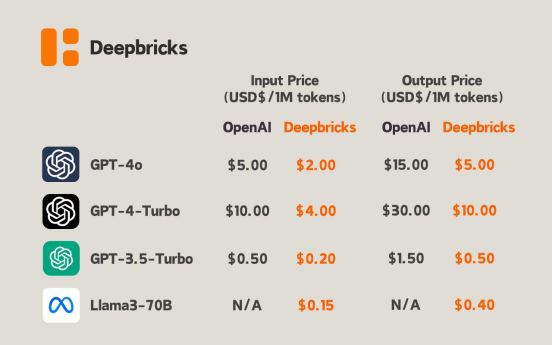
(图源:Deepbricks官网)
Lepton AI 创始人、阿里巴巴原副总裁贾扬清认为,企业在使用AI的时候,并不是成本驱动。不是因为API贵才没人用,而是因为企业首先得搞清楚怎么用来产生业务价值,否则的话,再便宜也是浪费。
若单纯的价格不具有吸引力,客户使用哪家大模型将取决于什么?
一位中间件的创业者向光子星球表示:“最主要看模型效果,如果模型效果太差再便宜也不能使用。”
还有海外的AI创业者直接跟光子星球说,国外用ChatGPT,因为能力强;国内用文心一言,因为能满足合规需求。
于是,价格仅仅是企业选择大模型其中一个因素。
同样在云计算和SaaS时代,往往能够留住客户的不是低价,而是更深层次的绑定关系或者利益关系。例如,当企业采用了火山引擎的豆包模型,是否就能在抖音投流享受到优惠权;接入通义千问,其产品是否就能与阿里生态打通,获得更多资源支持?
企业用户选择大模型的同时,也在权衡厂商的各自优势。大模型能力的高低成为了其次,更重要的是选择这家厂商能给其业务带来多少增长,在该厂商的产业链之下能获得多大的收益。
到最后还是要拿结果说话,正如贾扬清所言,“也许不是最便宜的赢得商战,而是能落地的赢得利润。”

